企业实现大数据分析效果关键的五个要素 数据处理与存储支持服务深度解析
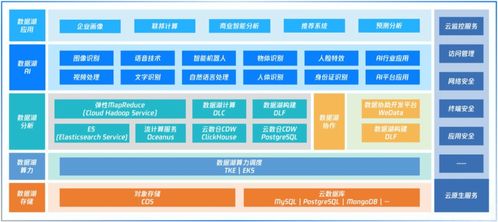
在当今数据驱动的商业环境中,大数据分析已成为企业提升决策质量、优化运营效率和发掘增长机会的核心引擎。许多企业在推进数据分析项目时,常因基础支持服务不到位而难以实现预期价值。其中,数据处理和存储支持服务是整个分析价值链的基石。本文将聚焦于实现大数据分析效果的五个关键要素,并深入剖析数据处理与存储支持服务在其中扮演的核心角色。
一、 数据整合与治理能力:构建可信的数据基石
高质量的分析始于高质量的数据。企业内外部数据源往往分散、异构且标准不一。数据处理支持服务首先体现在强大的数据整合与治理能力上。这包括:
1. 多源异构数据集成:通过ETL/ELT工具、数据管道和API接口,将来自业务系统、物联网设备、社交媒体等不同源头的数据进行高效汇聚。
2. 数据清洗与标准化:自动识别并处理数据中的缺失值、异常值和重复记录,并按照统一的标准和业务规则进行格式化,确保数据的一致性与准确性。
3. 元数据管理与数据血缘:建立企业级数据目录,清晰定义数据的含义、来源、转换过程与关联关系,实现数据的可追溯与透明化管理,为分析提供可信上下文。
强大的数据处理能力,将原始“数据原料”转化为可供分析的“精炼数据”,是产出可靠洞察的前提。
二、 弹性可扩展的存储架构:应对海量数据洪流
数据的体量、速度和多样性持续增长,对存储系统提出严峻挑战。存储支持服务的关键在于提供弹性可扩展的架构:
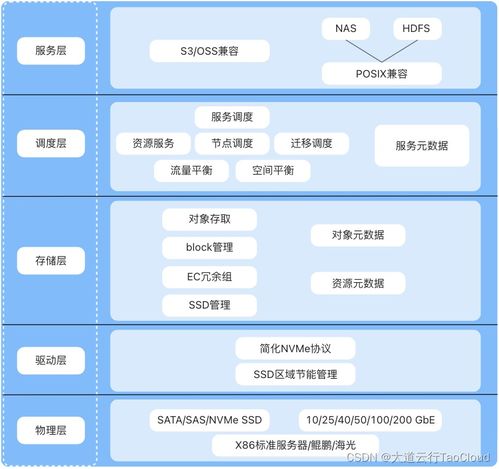
- 分层存储策略:根据数据的热度(访问频率)和价值,采用分层存储方案。例如,将热数据(实时分析所需)存放于高性能的分布式文件系统(如HDFS)或内存数据库中;将温数据存放于云对象存储或数据湖;将冷数据(归档历史)存放于成本更低的磁带库或冷存储中,实现成本与性能的最佳平衡。
- 数据湖与数据仓库的融合:现代架构趋向于将灵活、低成本的数据湖(存储原始和半结构化数据)与高性能、强Schema的数据仓库(存储治理后的分析型数据)相结合。数据处理服务需支持数据在湖与仓之间顺畅流动,形成“湖仓一体”的格局,兼顾探索性分析与标准化报表的需求。
- 无限水平扩展能力:存储系统应能通过增加节点的方式近乎线性地扩展容量和吞吐量,以应对未来数据量的爆发式增长,避免成为分析瓶颈。
三、 高性能计算与处理引擎:驱动实时智能分析
从存储中快速提取价值,离不开强大的计算处理引擎。这要求数据处理服务提供:
- 多样化计算框架支持:能够支持批处理(如Spark)、流处理(如Flink、Kafka Streams)、交互式查询(如Presto/Trino)和图计算等多种计算范式,满足从T+1报表到实时风险监控、复杂图关系挖掘等不同场景的分析需求。
- 资源管理与调度优化:通过YARN、Kubernetes等资源调度器,实现计算资源的弹性分配、任务队列管理和优先级调度,确保关键分析任务获得充足资源,最大化集群整体利用率。
- 近存储计算与向量化执行:将计算任务推送到数据所在的存储节点执行,减少数据网络传输开销;同时利用CPU的SIMD指令集进行向量化计算,大幅提升数据处理吞吐率。
四、 安全、合规与数据生命周期管理
随着数据法规(如GDPR、个保法)日趋严格,数据处理与存储必须内置安全与合规基因。关键要素包括:
- 全方位安全防护:涵盖数据传输加密、静态数据加密、细粒度的访问控制(基于角色或属性的权限管理)、完整的操作审计日志,防止数据泄露与未授权访问。
- 数据合规性自动化:集成数据脱敏、匿名化、假名化工具,自动识别和分类敏感个人信息(PII),并执行数据保留策略与合规删除,满足“被遗忘权”等法规要求。
- 智能化的数据生命周期管理:自动根据预定义的策略,将数据在不同存储层间迁移、归档或销毁,在满足合规要求的持续优化存储成本。
五、 可观测性与运维管理:保障分析服务高可用
稳定、可靠的数据处理与存储平台是业务连续性的保障。这需要:
- 全面的可观测性:提供集群健康度、资源使用率、作业执行状态、数据流水线延迟等指标的实时监控与告警,并具备深度的问题诊断与根因分析能力。
- 自动化运维与弹性自愈:实现资源的自动扩缩容、故障节点的自动检测与隔离、关键服务的自动重启与恢复,最大限度地减少人工干预和停机时间。
- 成本管理与优化:提供清晰的数据存储与计算成本分摊视图,识别成本驱动因素,并给出优化建议(如清理无用数据、调整任务资源配置),让大数据分析在可控的成本下高效运行。
###
企业大数据分析的成功,远不止于引入先进的算法和可视化工具。坚实、智能、安全且高效的数据处理与存储支持服务,是承载所有上层分析应用的“数字地基”。通过构建涵盖数据整合治理、弹性存储、高性能计算、安全合规与智能运维这五大关键要素的支撑体系,企业才能将海量、混沌的数据真正转化为可行动的智慧,在竞争中赢得先机。投资和持续优化这一基础层,是实现数据价值最大化的必经之路。
如若转载,请注明出处:http://www.soool27.com/product/3.html
更新时间:2026-06-19 04:04:34